I am going to discuss about how i implemented Bag of Visual Words[1], to categorize images using python, openCV and Scikit-learn. You can find the code for it here.
Implementing BagOfVisualWords mainly involves these steps:
- Extracting Features from Images.
- Getting Descriptors of features, which are used to represent the features.
- Constructing Vocabulary which contains visual words, which are nothing but cluster centres.
- To extract clusters, first we need data. I have used Caltech-101 dataset for images. I randomly took 1000 images, extracted features of those 1000 images using SIFT. Now we have data, we need to extract cluster centres for data. I used K-Means Clustering algorithm for this purpose. I ran the K-Means clustering algorithm on the data(i.e features of images), which seperated the data into various clusters.
- Representing each image as a feature vector.
- For each image we extract the features, and say there are 100 clusters. We create a feature vector of shape 1X100, and set all values of vector to 0. Now for each feature of the image, we check which cluster center it is nearest to, and say if it is nearest to 88th cluster center, we increase the value of 88th index in the feature vector by 1. In the end, we get a feature vector, which represents the image.
- Training Classifier using feature Vectors of Images and their labels, and then predicting the labels of feature Vectors of Unknown Images.
- Now, i have created a training and testing data-set using Caltech101. The training-testing ratio is 80-20. i.e, i am extracting the feature Vectors of all the 100 images in the dataset, but i am showing labels only for 80 images and asking the classifier to predict for other 20 images.I have used SVM of Scikit library for classification purpose.
Results:
| Number of categories | Accuracy | No of clusters used |
|---|---|---|
| 3 | 83% | 600 |
| 3 | 85% | 800 |
| 4 | 76% | 600 |
| 4 | 76% | 800 |
| 5 | 81% | 600 |
| 5 | 80% | 800 |
| 6 | 67% | 600 |
| 6 | 67% | 600 |
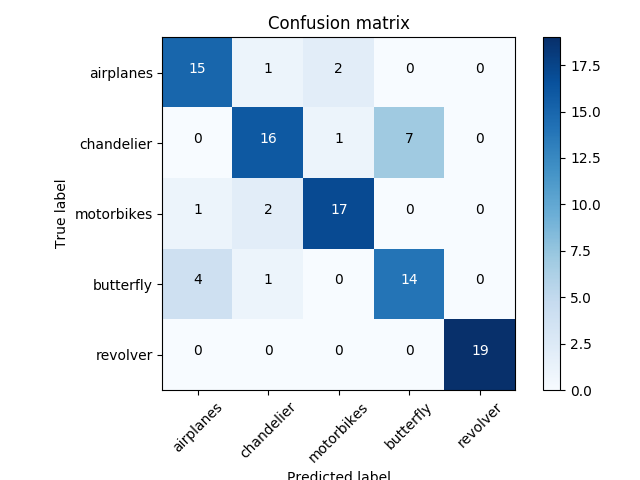
- Please check the results folder for the confusion matrices obtained. ex: confusion matrix of 5 categories with 600 clusters. *
i have included doc-strings for each function in the code, which can help in understanding the code.
For more details regarding how to run the code, please refer to the README in the code repository.
References:
- (1)[https://www.cs.cmu.edu/~efros/courses/LBMV07/Papers/csurka-eccv-04.pdf].
Feel free to drop an email, if you find any mistakes or have suggestions regarding my approach :).